[T] Naive Bayes Sınıflandırma Algoritması(Bölüm 2-Pratik)
Bu yazıda Naive Bayes sınıflandırma algoritmasını kullanarak atılan bir mesajın(sms) spam olup olmadığını tahmin eden bir model geliştireceğiz. Algoritmanın nasıl çalıştığını anlamak isterseniz 1.Bölümü okumanızı tavsiye ederim.
Sınıflandırma algoritmasını, python programlama dilinde scikit-learn(sklearn) kütüphanesini kullanarak kodlayacağız.Verileri okumak için de pandas kütüphanesini kullanacağız.Bu yazımda kullanacağım veri kümesine Kaggle veya UCI adreslerinden ulaşabilirsiniz.Ben birinci linki kullanacağım.
Makine öğrenmesi algoritmaları input olarak sayısal değerler kullandığı ve bu problemde metinsel veri ile uğraşacağımız için verinin sayısal değerlere dönüştürülmesi gerekiyor. Bu dönüşüm için bag of words modelini kullanacağız.
Bag of words model
Bu yöntemde elimizdeki her bir mesajı kelime kelime ayırıyoruz(tokenize) ve bu kelimelerin mesajlar içerisinde kaç defa geçtiğini gösteren bir sözlük(dictionary) oluşturuyoruz.Sözlük, mesajların içerisinde bulunan kelimelerden oluşuyor. Bundan sonra da her bir mesaj için encoding işlemini yapıyoruz. Kısaca sözlükteki kelimelerin ilgili mesajın içinde olup olmadığını gösteriyoruz. Eger sözlükteki kelime, mesajın içerisinde var ise ilgili indise sözlükteki sayısal karşılığını yazıyoruz(burada sayısal karşılık, ilgili kelimenin kaç defa geçtiği(count)), eğer kelime mesajın içinde yoksa 0 yazıyoruz.
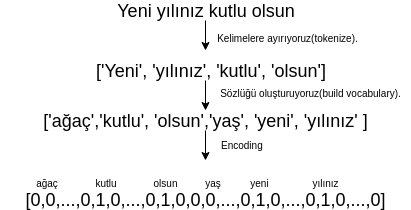
Not: Burada sözlük kavramını kelime haznesi yani bildiğimiz kelimeler anlamında kullandım.
Yazının devamında bu modeli scikit-learn kütüphanesinin bize sağlamış olduğu,
- CountVectorizer
sınıfı ile inceleyeceğiz.
Kütüphanelerin eklenmesi
İlgili kütüphaneleri yeri geldikçe ekleyeceğiz.
import numpy as np # Lineer cebir islemleri
import pandas as pd # Verileri okumak için
İlk önce pandas kütüphanesi yardımıyla verimizi okuyalım.
df = pd.read_csv("spam.csv", encoding='ISO-8859-1')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5572 entries, 0 to 5571
Data columns (total 5 columns):
v1 5572 non-null object
v2 5572 non-null object
Unnamed: 2 50 non-null object
Unnamed: 3 12 non-null object
Unnamed: 4 6 non-null object
dtypes: object(5)
memory usage: 217.7+ KB
df['v1'][:5]
0 ham
1 ham
2 spam
3 ham
4 ham
Name: v1, dtype: object
Verimiz ile alakali bilgilere bakalım. Genel bir bilgi almak istersek info() fonksiyonunu kullanabiliriz. Sütun bazlı bilgi almak istersekte sütun ismini kullanıp erişim sağlayabiliriz. Burada v1 sütunu verimizin etiketini(label) yani mesajın spam olup olmadığı bilgisini tutuyor. Görüldüğü üzere isimlendirilmemiş fazladan 3 sütunumuz var. Bunun sebebi, bazı mesajlar uzun olduğu için sütun dışına taşıyor.Bu sütunları verinin içinden çıkartalım. Çıkardığımızda ordaki veriler kaybolmaz mı diye düşünebilirsiniz. Bunu da pratik olması açısından size bırakıyorum :)
df.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)
Tekrardan sütunlara bakalım.
df.columns
Index(['v1', 'v2'], dtype='object')
Sütün isimlerinin daha açıklayıcı olması için isimlerini değiştirelim.
df.rename(columns={'v1':'Etiket', 'v2': 'Mesajlar'})[:3]
| Etiket | Mesajlar | |
|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... |
| 1 | ham | Ok lar... Joking wif u oni... |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... |
df['v1'] = df.v1.map({'ham':0, 'spam': 1})
Simdi de verimizi etiket(label) ve giriş değerlerine(input) ayıralım.
X = df.iloc[:,1] # Butun satırlar ve 1. sutunu al.
y = df.iloc[:,0] # Butun satırlar ve 0. sutunu al, python'da indislerin 0'dan basladigini hatirlatmak isterim.
X ve y’nin iceriklerine ve boyutlarına bakalım.
X[:5]
0 Go until jurong point, crazy.. Available only ...
1 Ok lar... Joking wif u oni...
2 Free entry in 2 a wkly comp to win FA Cup fina...
3 U dun say so early hor... U c already then say...
4 Nah I don't think he goes to usf, he lives aro...
Name: v2, dtype: object
y[:5]
0 0
1 0
2 1
3 0
4 0
Name: v1, dtype: int64
X.shape
(5572,)
y.shape
(5572,)
Simdi de verimizi egitim ve sınama verisi olarak ayıralım. Ben %70’e %30 seklinde bir ayrım yaptım. Bu parametreyi değişik rakamlarla da deneyip sonuçları karşılaştırabilirsiniz.
Burada jupyter notebook’un önemli bir özelliğinden bahsetmek istiyorum. Kulllanmak istediğiniz bir fonksiyonun başına ? koyduğunuzda o fonksiyona ait dökümanı açar. Fonksiyonun nasıl kullanıldığı, hangi parametreleri aldığı, geriye nasıl bir değer döndürdüğü ve kullanım örnekleri ile ilgili bilgiler alabilirsiniz. Dilerseniz random_state=42 nin ne anlama geldiğine de bakabilirsiniz.
from sklearn.model_selection import train_test_split
#?train_test_split
x_train, x_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=42)
Bag of words modelinin uygulanması
CountVectorizer sınıfını kullanacağımızdan bahsetmiştim. Şimdi bu sınıfı ekleyelim.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
Eğitim verimiz üzerinden sözlüğümüzü oluşturuyoruz. ? kullanarak fonksiyon hakkında bilgi alabileceğimizi tekrardan hatırlatmak isterim.
#?vectorizer.fit(x_train)
vectorizer.fit(x_train)
CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
Simdi de sözlükteki ilk ve son 5 kelimeye bakalım. Burada bir şeye dikkatinizi çekmek isterim. Bu kelimelerin, mesajlar içerisinde kaçar defa geçtiği bilgisi burada yok, aslında biz özniteliklere(features) bakmış olduk.
vectorizer.get_feature_names()[:5]
['00', '000', '000pes', '008704050406', '0089']
vectorizer.get_feature_names()[-5:]
['ûªve', 'ûï', 'ûïharry', 'ûò', 'ûówell']
Gerçek anlamda sözlüğe bakmak istersek ‘vocabulary_’ özelliğini kullanabiliriz.
#vectorizer.vocabulary_
Modelimize geçmeden önce son bir adımımız kaldı. Oluşturmuş olduğumuz sözlüğü kullanarak eğitim ve test verilerini encode etmemiz gerekiyor. Bu işlemi transform() fonksiyonunu kullanarak yapabiliriz.
x_train_tr = vectorizer.transform(x_train)
x_test_tr = vectorizer.transform(x_test)
type(x_test_tr)
scipy.sparse.csr.csr_matrix
Gördüğümüz üzere verilerimiz sparse matrix olarak tutuluyor. Bu matrisin içerisinde çok fazla 0 olduğu için verimlilik açısından bu yol tercih edilmiş. toarray() fonksiyonunu kullanarak verilerin encode edilmiş halini görebiliriz.
x_test_tr.toarray()
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])
Modeli oluşturma ve tahmin yapma
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
model = MultinomialNB()
model.fit(x_train_tr, y_train)
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
Naive-Bayes sınıflandırma algoritması için modelimizi oluşturduk ve fit() metodunu kullanarak eğittik. Şimdi de modelimize daha önce görmediği test verilerini verelim ve nasıl performans gösterdiğini ölçelim.
prediction = model.predict(x_test_tr)
accuracy_score(y_test, prediction)
0.98205741626794263
Modelimiz %98 doğruluk ile çalıştı.
Sonuçlar
Bu yazıda bag of words modelini kullanarak metinsel verilerin sayısal verilere nasıl dönüştürüldüğünü ve sınıflandırma algoritmasında nasıl kullanılacağını görmüş olduk. Modelimizin performansını geliştirmek için
- n-gram modeline bakılabilir,
- mesajların içerisinden stop_word’ler cıkarılabilir(nltk kütüphanesine bakabilirsiniz).
Yazımda hatalı olduğunu düşündüğünüz yerler olursa yorumlarda belirtmeyi unutmayın. Okuduğunuz için teşekkürler!