[T] Kaggle: Felaketten Çıkarılan Dersler
Merhabalar, bugün sizler ile Kaggle‘a giriş yapacak ve bu platformun ‘Hello World’ problemi olarak bilinen Titanic: Machine Learning from Disaster problemi üzerinden makine öğrenmesinin temellerini pratik olarak uygulamaya çalışacağız.
Bu yazı boyunca
- pandas kütüphanesi ile veri yükleme, veriyi tanıma, yeni özniteliklerin oluşturulması
- matplotlib ve seaborn kütüphanesi ile veriyi görselleştirme,
- sklearn kütüphanesi ile modellerin oluşturulması,
- veri içerisindeki eksik verilerin ele alınması
gibi konulara değineceğiz.
Yeri geldikçe yeni kavramlardan bahsedip, açıklamalarını yapmaya çalıştım. Daha fazla bilgi verebilmek adına da linkler ekledim. Hem okuyup hem de sonuçları direk gözlemlemek isterseniz bu linkteki jupyter notebook’u indirebilirsiniz.
Kütüphanelerin Eklenmesi
İlgili kütüphaneleri yeri geldiğince ekleyeceğiz.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
Verilerin okunması
Ilk olarak egitim ve sınama verilerimizi pandas kutuphanesi yardımıyla yukluyoruz.
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
# İşimizi kolaylaştırması açısından etiket(label) değerlerini ayrı bir şekilde tutuyoruz.
y = train_data.iloc[:, 1]
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
Verimiz hakkında genel bir bilgi almak istersek info() methodunu kullanabiliriz. Gördüğünüz üzere veri kümemiz, 5 adet object, 5 adet int, 2 adette float veri tipinden özniteliklerden(features) oluşuyor.
Şimdi de ilk 5 satıra bakalım.
train_data.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
Tabloya baktığımızda 12 adet sütun olduğunu görüyoruz. Bunlardan “Survived” sütunu bizim tahminde bulunacağımız sütun. Sütun isimlerine farklı bir yol ile de bakabiliriz.
train_data.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
Öznitelik Çıkarımı(Feature Extraction)
Eğer Titanik filmini izlediyseniz, filmden hatırlayacağınız üzere kadın ve çocukların botlara binme önceliği vardı. Bu yüzden cinsiyet(Sex) ve yaş(Age) bilgisinin hayatta kalma(Survived) konusunda önemli bir etkisi olabilir. Bu yüzden önce bunları inceleyerek başlayacağız. Bunun için pd.pivot_table() fonksiyonunu kullanacağız.
Devamında ise
- Pclass
- Embarked
- Fare
- SibSp
- Parch
- Cabin
- Title
sütunlarını inceleyeceğiz.
sex_pivot = train_data.pivot_table(index="Sex", values="Survived")
sex_pivot.plot.bar()
plt.show()
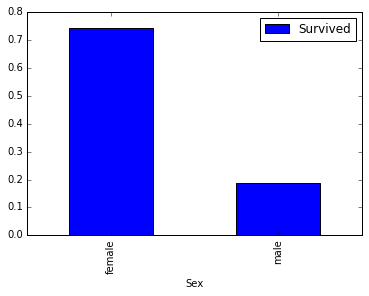
Burada gördüğünüz üzere kadın yolcuların hayatta kalma oranları erkek yolculara göre daha fazla.
Age sütununu inceleyelim.
train_data["Age"].describe()
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
train_data.shape
(891, 12)
Gördüğünüz üzere en küçük yaş 0.42 en büyük yaş ise 80. Yani yaş aralığımız 0.42 ile 80 arasında.
Burada dikkat etmemiz gereken bir diğer hususta count değeri. Normalde 891 satırımız var iken, “Age” sütununda 714 değer tanımlı. Yani bazı kişilerin yaş bilgisi elimizde yok. Bu probleme az sonra basit bir çözüm sunacağız.
Şimdi de “Age” sütununun histogramına bakalım.
survived = train_data[train_data["Survived"] == 1]
died = train_data[train_data["Survived"] == 0]
survived["Age"].plot.hist(alpha=0.5, color='red', bins=50)
died["Age"].plot.hist(alpha=0.5, color='blue', bins=50)
plt.legend(["Survived", "Died"])
plt.show()
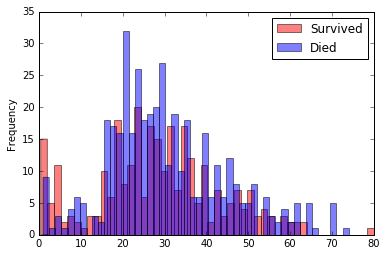
Bu histograma bakarak çok net çıkarımlar yapmak biraz güç ancak bazı yaş aralıkları için yolcuların hayatta kalma oranlarının daha fazla olduğunu görebiliyoruz(Kırmızı barların mavi barlardan daha yüksek olduğu yerler). Bu edindiğimiz bilginin bize fayda sağlaması için bazı aralıklar belirleyerek sürekli özniteliği, kategorik bir özniteliğe dönüştüreceğiz. Bunun için pd.cut() fonksiyonunu kullanacağız.
cut_points = [-1, 0, 5, 12, 18, 35, 60, 80]
label_names = ["Missing", "Baby", "Child", "Teen", "Young_adult", "Adult", "Senior"]
train_data["Age"] = train_data["Age"].fillna(-0.5)
train_data["Age_categories"] = pd.cut(train_data["Age"], cut_points, label_names)
test_data["Age"] = test_data["Age"].fillna(-0.5)
test_data["Age_categories"] = pd.cut(test_data["Age"], cut_points, label_names)
“Age” sütunundaki bazı değerlerin eksik olduğundan bahsetmiştik. DataFrame.fillna() fonksiyonu ile eksik değerlerin(NA/NaN) yerine -0.5 yazdık. İsterseniz bu veriyi daha farklı metodlar ile de doldurabilirsiniz.[1]
Eğitim verimizdeki “Age” sütununu kullanarak, “Age_categories” adında yeni bir öznitelik oluşturduk. Şimdi bu özniteliğin ilk 10 satırına bakalım.
train_data["Age_categories"][:10]
0 (18, 35]
1 (35, 60]
2 (18, 35]
3 (18, 35]
4 (18, 35]
5 (-1, 0]
6 (35, 60]
7 (0, 5]
8 (18, 35]
9 (12, 18]
Name: Age_categories, dtype: category
Categories (7, interval[int64]): [(-1, 0] < (0, 5] < (5, 12] < (12, 18] < (18, 35] < (35, 60] < (60, 80]]
Beklendiği üzere “Age_categories” sütunu 7 farklı aralık değerinden oluşuyor. Şimdi de yeni oluşturduğumuz sütun ile hayatta kalma arasındaki ilişkiye bakmak için tekrardan pivot_table() ile plot edelim.
age_cat_pivot = train_data.pivot_table(index="Age_categories", values="Survived")
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(221)
age_cat_pivot.plot(kind='bar', ax=ax)
ax = fig.add_subplot(222)
sex_pivot.plot(kind='bar', ax=ax)
plt.show()
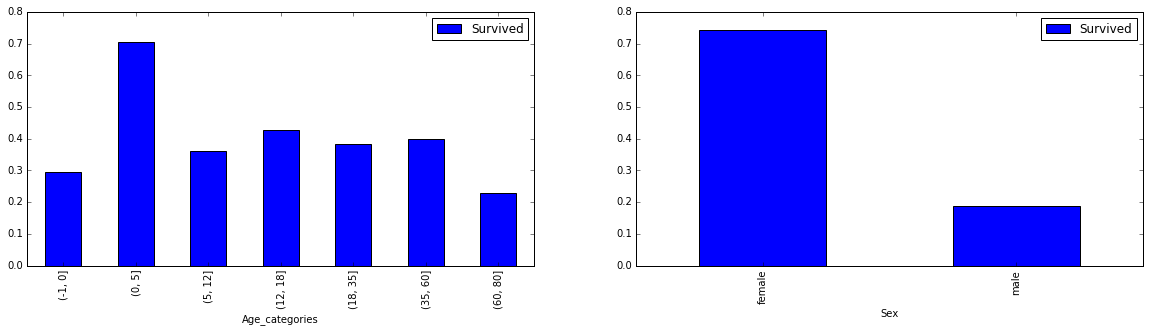
İlk başta bahsetmiş olduğumuz kadın ve çocukların hayatta kalma olasılığının daha fazla olduğunu burada da görüyoruz.
One-Hot Encoding
Sınırlı sayıda değer alan verilere kategorik veri deniyor. Örneğin insanların hangi marka arabaya sahip oldukları hakkında bir anket yapsanız sonuçlar kategorik olurdu(Toyota, Renault vs.). Çoğu makine öğrenme algoritmasını uygularken bu değerleri “encode” etmez isek hata ile karşılaşırız. One-Hot Encoding, kategorik verileri encode etmek için kullanılan yöntemlerden birisi.
| Toyota : | 1-0-0-0 |
| Renault : | 0-1-0-0 |
| Honda : | 0-0-1-0 |
| BMW : | 0-0-0-1 |
Yukarıda ki tabloda gördüğünüz üzere ilgili sınıfın olduğu indekse 1, geri kalanlara 0 yazıyoruz. Daha sonra oluşturduğumuz bu veriyi veri setimize yeni bir sütun olarak ekliyoruz. Biz de bu yazı boyunca bu yönteme başvuracağız. Bu yöntemi uygulamak içinse pd.get_dummies() fonksiyonunu kullanacağız.
Daha fazla bilgi almak isterseniz bu yazıyı okuyabilirsiniz.
def create_dummies(df, column_name):
dummies = pd.get_dummies(df[column_name], prefix=column_name)
df = pd.concat([df, dummies], axis=1)
return df
create_dummies() fonksiyonu bir DataFrame nesnesi ve sütun ismini alıyor. Sütun içerisindeki kategorik değerler için [dummy][1] değişkenler oluşturup, DataFrame’in sonuna ekliyor. “Age_categories”, “Sex” ve “Pclass” sütunları için bu fonksiyonu kullanalım. [1]: https://en.wikipedia.org/wiki/Dummy_variable_(statistics)
train_data = create_dummies(train_data, "Age_categories")
test_data = create_dummies(test_data, "Age_categories")
train_data = create_dummies(train_data, "Sex")
test_data = create_dummies(test_data, "Sex")
train_data = create_dummies(train_data, "Pclass")
test_data = create_dummies(test_data, "Pclass")
Pclass sütunu yolcuların hangi sınıfta yolculuk ettiğini gösteriyor. 3 farklı kategoriden oluştuğu için bu veriyi de encode ediyoruz.
Başlangıçta 12 sütunumuz varken şuan 25 sütunumuz var. Tabii ki bunların hepsi daha iyi bir model oluşturmamıza yardımcı olmuyor. İlerleyen kısımlarda bu karara nasıl vardığımızdan bahsedeceğim. Şimdilik devam edelim.
train_data.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked', 'Age_categories',
'Age_categories_(-1, 0]', 'Age_categories_(0, 5]',
'Age_categories_(5, 12]', 'Age_categories_(12, 18]',
'Age_categories_(18, 35]', 'Age_categories_(35, 60]',
'Age_categories_(60, 80]', 'Sex_female', 'Sex_male', 'Pclass_1',
'Pclass_2', 'Pclass_3'],
dtype='object')
cols = ["SibSp", "Parch", "Fare", "Cabin", "Embarked"]
train_data[cols].describe(include='all')
| SibSp | Parch | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 204 | 889 |
| unique | NaN | NaN | NaN | 147 | 3 |
| top | NaN | NaN | NaN | B96 B98 | S |
| freq | NaN | NaN | NaN | 4 | 644 |
| mean | 0.523008 | 0.381594 | 32.204208 | NaN | NaN |
| std | 1.102743 | 0.806057 | 49.693429 | NaN | NaN |
| min | 0.000000 | 0.000000 | 0.000000 | NaN | NaN |
| 25% | 0.000000 | 0.000000 | 7.910400 | NaN | NaN |
| 50% | 0.000000 | 0.000000 | 14.454200 | NaN | NaN |
| 75% | 1.000000 | 0.000000 | 31.000000 | NaN | NaN |
| max | 8.000000 | 6.000000 | 512.329200 | NaN | NaN |
Burda gördüğümüz üzere SibSp, Parch ve Fare sütunlarında herhangi bir eksiklik yok. Embarked sütununda 2 değer eksik. Cabin sütununda ise değerlerin büyük çoğunluğu eksik(204 değer var). Cabin sütunu ile daha sonra ilgileneceğiz.
Öncelikle Embarked sütunundaki boş olan 2 değeri, veri içerisinde en çok geçen(644 defa) değer olan “S” ile dolduralım. ve bu sütun için encoding işlemini uygulayalım.
train_data["Embarked"] = train_data["Embarked"].fillna("S")
test_data["Embarked"] = train_data["Embarked"].fillna("S")
train_data = create_dummies(train_data, "Embarked")
test_data = create_dummies(test_data, "Embarked")
Kaggle’da öznitelikler için olan açıklamaya baktığımızda şunlar yazıyor.
- sibsp # of siblings / spouses aboard the Titanic
-
parch # of parents / children aboard the Titanic
- SibSp: kardeş veya eş sayısı
- Parch: Ebeveyn veya çocukların sayısı
Kısaca biz yolcuların aileleri ile ilgili bilgilere sahibiz. Şimdi her yolcunun aile büyüklüğü ile hayatta kalma arasında bir ilişki olup olmadığına bakalım.
explore_cols = ["SibSp", "Parch", "Survived"]
explore = train_data[explore_cols].copy()
explore["family_size"] = explore[["SibSp", "Parch"]].sum(axis=1)
pivot = explore.pivot_table(index="family_size", values="Survived")
pivot.plot.bar(ylim=(0,1), yticks=np.arange(0,1,.1))
plt.show()
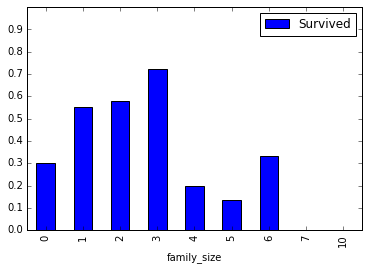
Gördüğünüz üzere yolculardan tek başına seyahat edenlerin %30’u hayatta kalmayı başarabilmiş. Bu bilgiyi kullanabilmek için “is_alone” isimli yeni bir sütun oluşturalım ve eğer yolcu, tek başına seyahat ediyorsa 1, değilse 0 ile gösterelim.
def process_family(df):
is_alone = []
for val in df[["SibSp", "Parch"]].sum(axis=1):
if val == 0:
is_alone.append(1)
else:
is_alone.append(0)
df["is_alone"] = is_alone
return df
train_data = process_family(train_data)
test_data = process_family(test_data)
Yeni oluşturduğumuz sütunu da encode edelim.
train_data = create_dummies(train_data, "is_alone")
test_data = create_dummies(test_data, "is_alone")
survived = train_data[train_data["Survived"] == 1]
died = train_data[train_data["Survived"] == 0]
survived["Fare"].plot.hist(alpha=0.5, range=[0, 200], color='red', bins=10)
died["Fare"].plot.hist(alpha=0.5, range=[0,200], color='blue', bins=10)
plt.legend(["Survived", "Died"])
plt.show()
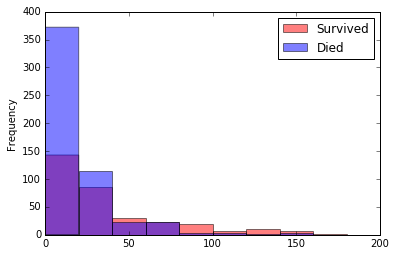
“Age” sütununa uygulamış olduğumuz yöntemi “Fare” sütunu için de uygulayalım.
cut_points = [0, 12, 50, 100, 1000]
label_names = ["0-12", "12-50", "50-100", "100+"]
def process_fare(df, cut_points, label_names):
df["Fare"] = pd.cut(df["Fare"], cut_points, labels=label_names)
return df
train_data = process_fare(train_data, cut_points, label_names)
test_data = process_fare(test_data, cut_points, label_names)
train_data = create_dummies(train_data,"Fare")
test_data = create_dummies(test_data, "Fare")
Evet şu ana kadar sadece sayısal verilerimizi hazırlamak için çaba gösterdik. Ancak verimiz sadece sayısal verilerden değil, aynı zamanda metinsel(text) verilerinden de oluşmakta. Bu problem için Cabin ve Name sütunlarına bakacağız.
Cabin sütunu ile başlayalım.
train_data["Cabin"][:10]
0 NaN
1 C85
2 NaN
3 C123
4 NaN
5 NaN
6 E46
7 NaN
8 NaN
9 NaN
Name: Cabin, dtype: object
Burada gördüğünüz üzere değer C85, C123, E46 gibi değerler var. İlk harf cabinin türünü belirtiyor. Bizim için önemli olabilecek bu bilgiyi kullanarak ‘Cabin_type’ isminde yeni bir sütun oluşturalım.
train_data["Cabin_type"] = train_data["Cabin"].str[0]
test_data["Cabin_type"] = test_data["Cabin"].str[0]
Cabin sütununun çok fazla NaN değer içerdiğinden daha önce bahsetmiştik. Bu değerleri de “Unknown” yani bilinmiyor olarak değiştirelim.
train_data["Cabin_type"] = train_data["Cabin_type"].fillna("Unknown")
test_data["Cabin_type"] = test_data["Cabin_type"].fillna("Unknown")
train_data = create_dummies(train_data, "Cabin_type")
test_data = create_dummies(test_data, "Cabin_type")
Aslında çok fazla eksik değer olduğu için bu sütunu direk çıkarabilirdik. Az sonra bunu nasıl yapabileciğimizden bahsedeceğim ancak çıkarmayacağım. Pratik olması açısından bu kısmı size bırakıyorum. Bu sütun ile hiç uğraşmadan direk çıkarabilir ve oluşturduğunuz modellerde iyileşme olup olmadığını gözlemleyebilirsiniz.
Şimdi de Name sütununa bakalım.
train_data["Name"][:5]
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
Name: Name, dtype: object
Burada gördüğünüz üzere yolcuların isimlerinde bazı ünvanlar var. Mr. , Mrs. , Miss. gibi…
Bu bilgileri elde etmek için Series.str.extract fonksiyonunu kullanıp Series.map fonksiyonu ile de “Title” adında yeni bir sütun oluşturacağız. Name sütununda Mr. Mrs. ‘ dan başlayıp Sir, Lady’e kadar giden bir ünvan bilgisi var. Biz bunları gruplamak ve biraz daha küçük bir ölçeğe sığdırmak amacıyla 6 gruba ayıracağız.
Bu işlemleri yaptıktan sonra da daha önce yapmış olduğumuz gibi encode edeceğiz.
# Büyük-küçük harfler ve nokta ile biten kelimeleri eşleştir.
pattern = '([A-Za-z]+)\.'
extracted_titles = train_data["Name"].str.extract(pattern, expand=False)
print(extracted_titles[:5])
titles = {
"Mr" : "Mr",
"Mme": "Mrs",
"Ms": "Mrs",
"Mrs" : "Mrs",
"Master" : "Master",
"Mlle": "Miss",
"Miss" : "Miss",
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Dr": "Officer",
"Rev": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Countess": "Royalty",
"Dona": "Royalty",
"Lady" : "Royalty"
}
train_data["Title"] = extracted_titles.map(titles)
extracted_titles = test_data["Name"].str.extract(pattern, expand=False)
test_data["Title"] = extracted_titles.map(titles)
0 Mr
1 Mrs
2 Miss
3 Mrs
4 Mr
Name: Name, dtype: object
train_data = create_dummies(train_data, "Title")
test_data = create_dummies(test_data, "Title")
Belirtmek isterim ki, bu bilgi de işimize yaramıyor olabilir. Tekrardan, pratik olması için bu kısmı da size bırakıyorum. Bu işlemleri hiç uygulamadan “Name” sütununu çıkarabilir ve oluşturacağınız farklı modeller ile bu veriyi tutup tutmama kararını verebilirsiniz.
Eşdoğrusallık(Collinearity)
Şu ana kadar mevcut bilgilerimizi kullanarak yeni sütunlar oluşturduk. Ancak yeni sütunlar ekledikçe eşdoğrusallık(collinearity) diye tabir edilen önemli bir problemi de eklemiş oluyoruz. Eşdoğrusallık, birden fazla özniteliğin benzer bilgiler tutmasından kaynaklanıyor. Örneğin, cinsiyet bilgisini encode ettiğimizde verimize ‘Sex_female’ ve ‘Sex_male’ adında 2 sütun daha eklemiştik. Burada Sex_female sütunu, ilgili kişinin cinsiyetini tutuyor. 1 ise kadın, 0 ise değil.
Aslında, biz bir insanın kadın olduğunu biliyorsak aynı zamanda erkek olmadığı bilgisini de elde etmiş oluyoruz. Bu yüzden bu 2 sütun birbiriyle yakından alakalı. Eğer biz bu haliyle modelimizi eğitirsek ezberleme(overfitting) dediğimiz problem ile karşılaşırız. Bu problemi engellemek adına bu 2 sütundan bir tanesini verimizden çıkarmalıyız.
Eşdoğrusallık, farklı öznitelikler arasında da olabilir. Bunu tespit etmenin genel yöntemlerinden biri heatmap.
Seaborn’un kendi dökümantasyonundaki kodu kullanarak heatmap’i oluşturalım.
def plot_correlation_heatmap(df):
corr = df.corr()
sns.set(style="white")
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
f, ax = plt.subplots(figsize=(11, 9))
cmap = sns.diverging_palette(220, 10, as_cmap=True)
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
plt.show()
plot_correlation_heatmap(train_data)
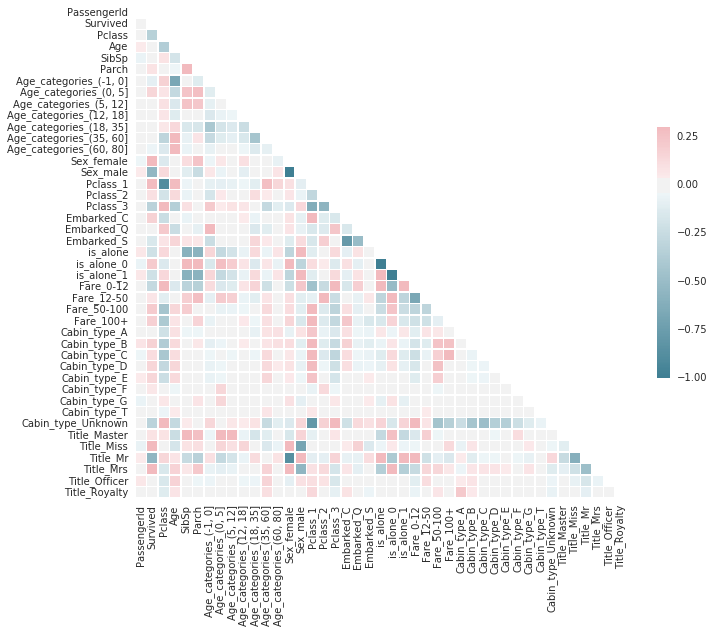
Burada koyu renkli kareler iki özniteliğin birbiriyle bağlantılı olduğunu gösteriyor.
- Sex_male ve Sex_female
- Title_Mr ve Title_Miss
- Pclass_2 ve P_class 3
- …
arasında yüksek korelasyon görülüyor. Bu sütunları verimizden çıkaracağız.
Bunu yapmadan önce özniteliklerin eski hallerini verimizden çıkaralım. Aslında bunu encode ettikten hemen sonra da yapabilirdik ancak ben bilgileri daha düzenli halde sunabilmek adına şimdi yapmayı daha uygun gördüm.
# Birazdan kaggle'a tahminlerimizi kaydedeceğiz. Orada kullanabilmek adına yolcuların id'lerini çıkarmadan
# önce saklayalım.
passenger_id = test_data["PassengerId"]
drop_cols = ['PassengerId','Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked', 'Age_categories', 'is_alone',
'Cabin_type', 'Title']
train_data = train_data.drop(drop_cols, axis=1)
test_data = test_data.drop(drop_cols, axis=1)
train_data = train_data.drop(["Survived"], axis=1)
Şimdi de yeni oluşturduğumuz özniteliklerden, arasında yüksek korelasyon olanları verimizden çıkaralım.
Bu kısımda, yukarıda bulunan heatmap’e bakarak koyu renkli karelerin hangi 2 özniteliğin birleştiği yerde olduğuna bakabilir ve tek tek bunları çıkarabiliriz. Ancak bu işlemi kolaylaştırabilecek bir yöntemden bahsetmek istiyorum. Scikit-learn kütüphanesinin sunmuş olduğu RFECV sınıfı ile optimize edilmiş öznitelikleri bulup, bu öznitelikler ile modelimizi eğiteceğiz. Burada isterseniz bu yöntemi hiç kullanmayıp drop metodu ile de çıkarabilirsiniz.
RFECV sınıfı, bir tahmin ediciyi(estimator) parametre olarak alıyor. İlk olarak bu tahmin edici ile tüm öznitelikleri kullanarak bir tahminde bulunuyor. Bu işlemden sonra her özniteliğin bir ağırlığı oluyor. Daha sonra en az önemli olan(ağırlığı en düşük olan) öznitelikler çıkarılıyor ve bu işlem istenilen öznitelik sayısına ulaşıncaya kadar devam ediyor.
train_data = train_data.drop(["Cabin_type_Unknown", "Cabin_type_T"], axis=1)
test_data = test_data.drop(["Cabin_type_Unknown"], axis=1)
from sklearn.feature_selection import RFECV
from sklearn.ensemble import RandomForestClassifier
import xgboost as xgb
rf = RandomForestClassifier()
selector = RFECV(rf, cv=10)
selector.fit(train_data, y)
opt_cols = train_data.columns[selector.support_]
opt_cols
Index(['Age_categories_(0, 5]', 'Age_categories_(18, 35]',
'Age_categories_(35, 60]', 'Sex_female', 'Sex_male', 'Pclass_1',
'Pclass_3', 'Embarked_C', 'Embarked_S', 'is_alone_0', 'Fare_0-12',
'Fare_50-100', 'Cabin_type_E', 'Title_Miss', 'Title_Mr'],
dtype='object')
Optimize edilmiş sütunlarımızı elde ettik. Yukarıda, Sex_female ve Sex_male gibi sütunların modelimiz için problem olacağını söylemiş ve çıkarmamız gerektiğinden bahsetmiştik. Ancak RFECV sınıfı bu iki bilgiyi de tutmak istedi. Biz de bu karara saygı duyup, modellerimizi bu öznitelikler ile eğiteceğiz.
Modellerin oluşturulması
Şimdiye kadar özniteliklerimiz hakkında birçok yorumda bulunduk ve nasıl fayda sağlayabileceğimizden bahsettik. Artık modellerimizi oluşturabiliriz.Scikit-learn kütüphanesinin sağlamış olduğu,
sınıflarını kullanacağız. Bu aşamadan sonra istediğiniz yöntem ile modellerinizi oluşturabilir ve hangisinin daha iyi sonuç verdiğini kıyaslayabilirsiniz.
Önce ihtiyacımız olan sınıfları ekleyelim.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
Burada eğitim verimizi %80’e %20 olarak ayıracağız ve modellerimizi %80’lik kısım ile eğiteceğiz. %20’lik kısım ile de modelimizin nasıl çalıştığını kontrol edeceğiz. Bunu yapmak için train_test_split fonksiyonunu kullanalım.
x_train, x_test, y_train, y_test = train_test_split(train_data[opt_cols], y, test_size=0.2, random_state=42)
predictions = []
models = []
lr = LogisticRegression()
lr.fit(x_train, y_train)
lr_pred = lr.predict(x_test)
predictions.append([pd.DataFrame(lr_pred), 'LR'])
models.append(lr)
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
knn_pred = knn.predict(x_test)
predictions.append([pd.DataFrame(knn_pred), 'KNN'])
models.append(knn)
rfc = RandomForestClassifier()
rfc.fit(x_train, y_train)
rfc_pred = rfc.predict(x_test)
predictions.append([pd.DataFrame(rfc_pred), 'RFC'])
models.append(rfc)
Ve sonunda modellerimizi eğittik. İşlerin yolunda gidip gitmediğini kontrol etmek için modellerimizin doğruluğunu kontrol edelim.
for pred in predictions:
acc = accuracy_score(y_test, pred[0])
print(pred[1], ' : ', acc)
LR : 0.7932960893854749
KNN : 0.8379888268156425
RFC : 0.7877094972067039
Görünenlere göre K-Nearest Neighbour en iyi çalışan algoritma. Ancak bu başarıyı gerçek test verisi üzerinde gösterebilecek mi ?
Bu sorunun cevabını öğrenmek için, kaggle’a yükleyebilmek adına tahminlerimizi oluşturalım.
def save_submission_file(models):
for model in models:
prediction = model.predict(test_data[opt_cols])
df = {"PassengerId": passenger_id, "Survived": prediction}
submission = pd.DataFrame(df)
name = "submission" + model.__class__.__name__ + ".csv"
submission.to_csv(name, index=False)
save_submission_file(models)
Ben, Logistic Regression ile kaggle üzerinde %78.468 doğruluk elde ettim. Siz de farklı modeller, farklı öznitelikler vs. ile deneyerek gözlemlerinizi yorumlarda belirtebilirsiniz. Okuduğunuz için teşekkürler!
Faydalı linkler: